Dalam beberapa tahun terakhir, kemunculan Gemini dan GPT-5 telah meningkatkan akurasi terjemahan AI secara drastis. Namun, ketika mencoba mengintegrasikan teknologi ini ke dalam layanan atau sistem bisnis perusahaan, muncul berbagai masalah operasional yang serius, terlepas dari sekadar baik atau buruknya akurasi terjemahan.
1. Keterbatasan yang Muncul dari Prasyarat Integrasi API
Jika ingin mengotomatisasi atau mensistematisasi proses penerjemahan, Anda tidak bisa sekadar menyalin dan menempelkan secara manual ke UI. Pada dasarnya, AI akan diakses melalui API (Application Programming Interface).
Namun, API adalah proses independen yang memberikan "satu respons untuk setiap permintaan". API tidak "mengingat terjemahan sebelumnya" seperti halnya manusia. Sifat stateless (tidak menyimpan status) ini menimbulkan masalah "konsistensi" berikutnya.
2. "Gaya" dan "istilah" yang berubah setiap kali API dipanggil
AI (terutama tipe LLM) memiliki sifat di mana meskipun diberikan kalimat yang sama, hasil keluarannya bisa sedikit berbeda tergantung pada parameter saat itu (seperti Temperature) atau interpretasi konteks.
- Campuran gaya formal (desu/masu) dan gaya informatif (de aru)
- Istilah teknis tertentu kadang diterjemahkan sebagai A, kadang sebagai B
Untuk mencegah hal ini, sangat penting membangun "lapisan kontrol" yang secara dinamis memasukkan "glosarium" saat memanggil API, atau menetapkan nada yang ketat melalui sistem prompt.
3. Dilema antara "Biaya" dan "Kualitas": Sulitnya Pembaruan Parsial
Ketika menerjemahkan konten dengan frekuensi pembaruan tinggi seperti situs web atau manual, menerjemahkan ulang seluruh teks setiap kali sangat tidak efisien.
- Masalah biaya: Meskipun hanya satu baris yang diperbaiki dalam dokumen puluhan ribu karakter, jika seluruh dokumen diterjemahkan ulang, biaya API akan membengkak.
- Masalah kualitas: Jika seluruh teks diterjemahkan ulang, ada risiko gaya bahasa pada bagian yang tidak diperbaiki juga ikut berubah.
Oleh karena itu, diperlukan mekanisme untuk "mengidentifikasi dan menerjemahkan hanya bagian yang diperbarui (terjemahan diferensial)", namun hal ini menimbulkan tantangan besar berikutnya.
4. Terputusnya Konteks: Dampak Negatif dari Terjemahan Tambal Sulam (Patchwork)
Jika hanya bagian yang diperbarui saja yang diberikan ke AI, AI tidak dapat memahami "konteks sebelum dan sesudah" bagian tersebut.
Contoh: Meskipun kalimat sebelumnya ditulis dengan gaya formal, satu kalimat baru yang ditambahkan malah diterjemahkan dengan gaya sopan. Atau, jika AI tidak mengetahui apa yang dimaksud oleh kata ganti (seperti itu, dia, atau mereka), maka bisa terjadi kesalahan terjemahan.
Untuk mencegah terjadinya "patchwork" seperti ini, diperlukan implementasi tingkat lanjut yang tidak hanya memberikan data perbedaan yang akan diterjemahkan, tetapi juga "terjemahan yang sudah ada di sekitarnya" sebagai konteks (informasi latar belakang) kepada AI.
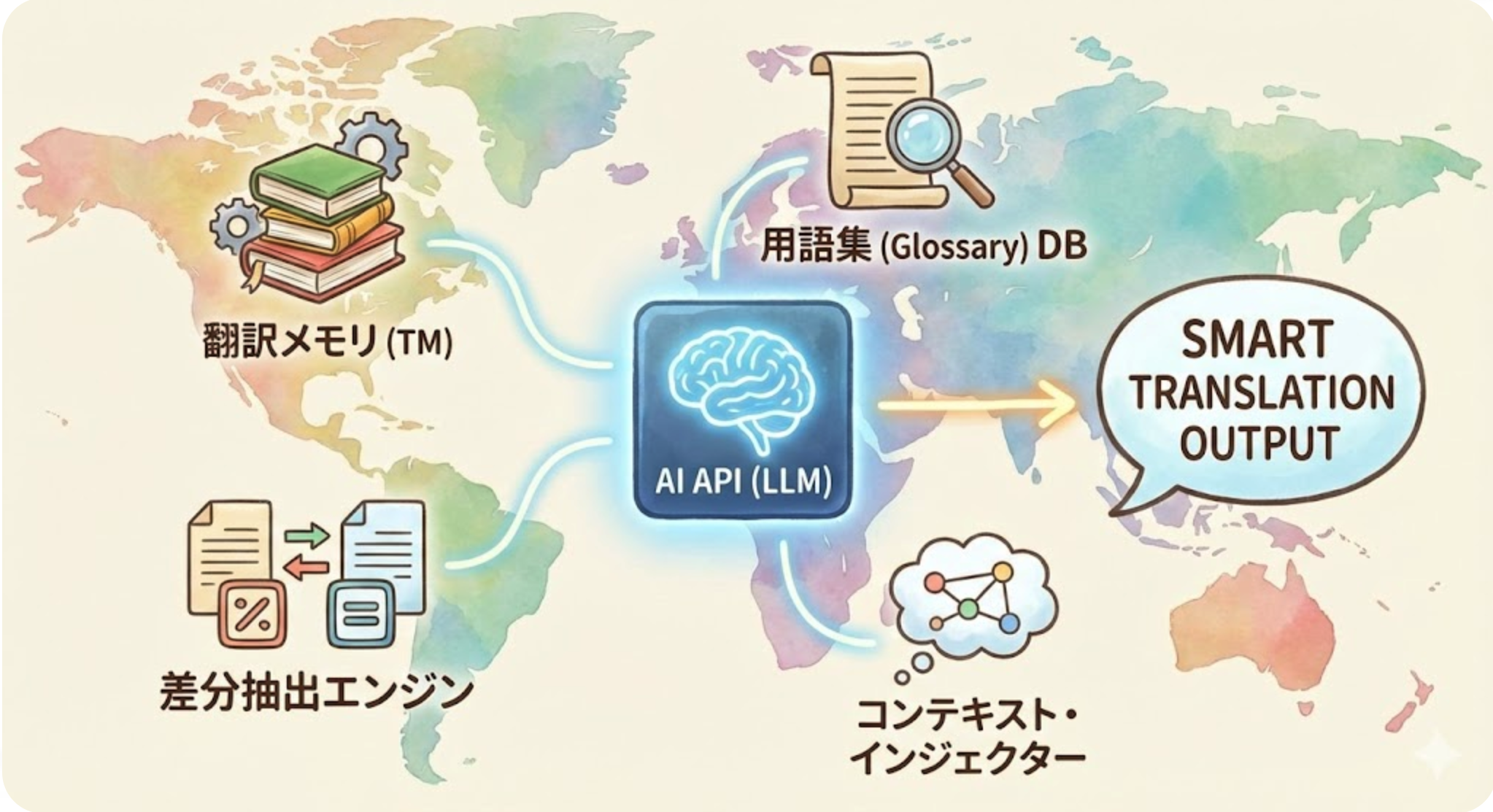
Pendekatan untuk Mengatasi Tantangan
Untuk mengatasi masalah-masalah ini, diperlukan sudut pandang "orkestrasi penerjemahan" seperti di bawah ini, bukan sekadar pemanggilan API biasa.
- Pemanfaatan Memori Terjemahan (TM): Mengelola hasil terjemahan sebelumnya dalam basis data, sehingga kalimat yang sama tidak diterjemahkan ulang dan kalimat serupa dapat dijadikan referensi.
- Pendekatan RAG (Retrieval-Augmented Generation): Saat menerjemahkan, secara dinamis menyuntikkan glosarium dan praktik terbaik sebelumnya ke dalam prompt.
- Penyuntikan konteks: Saat melakukan terjemahan diferensial, beberapa baris sebelum dan sesudahnya diberikan kepada API sebagai "informasi referensi" untuk menyelaraskan nada.
Ringkasan
Mengintegrasikan terjemahan AI ke dalam sistem bukan sekadar konversi bahasa, melainkan tantangan rekayasa tentang bagaimana mengelola konsistensi.
Jangan terlalu percaya diri dengan anggapan bahwa "karena AI pasti sempurna"; pahami karakteristik API, lalu bangunlah mekanisme untuk menjaga konteks dan mengendalikan penggunaan istilah. Itulah kunci untuk berhasil melakukan ekspansi multibahasa dengan kualitas tinggi.

