近年隨著Gemini和GPT-5等技術的出現,AI翻譯的精確度有了飛躍性的提升。然而,當這些技術要整合進自家服務或業務系統時,除了單純的「翻譯準確度」之外,還會浮現出許多實際運用上的嚴峻問題。
1. 「API串接」這個大前提所帶來的限制
當要將翻譯自動化或系統化時,不可能手動在UI上進行複製貼上。基本上會透過API(應用程式介面)來呼叫AI。
然而,API 是針對「一次請求」回傳「一個回應」的獨立處理。它並不會像人類一樣「記得上一次的翻譯內容」。這種 無狀態(Stateless) 的特性,會引發接下來的「一致性」問題。
2. 每次呼叫 API,「語氣」與「用詞」都會改變
AI(特別是大型語言模型)即使輸入相同的句子,根據當時的參數(如 Temperature 等)或對語境的解讀,輸出的結果也會有細微的差異。
- 敬體語氣與書面語氣混雜
- 特定的專業術語有時被翻譯為A,有時被翻譯為B
為了防止這種情況,必須在API呼叫時動態導入用語集(Glossary),或是在系統提示中嚴格指定語氣,建立控制層。
3. 「成本」與「品質」的兩難:差異更新的困難
在翻譯像是網站或操作手冊等更新頻率高的內容時,每次都進行「全文重新翻譯」是非常沒有效率的。
- 成本問題:即使只修改了數萬字文件中的一行,若重新翻譯全文,API費用也會大幅增加。
- 品質問題:如果重新翻譯全文,甚至連沒有修改的部分用詞也可能會發生變化,存在這樣的風險。
因此,「只針對更新的部分進行翻譯(差異翻譯)」 的機制就變得不可或缺,但這也帶來了下一個重大課題。
4. 文脈的斷裂:拼湊(拼布)翻譯的弊端
如果只將更新的部分交給AI,AI將無法掌握該部分的前後文脈。
舉例來說:前面的句子是以書面語寫成,但新增加的那一句卻被翻譯成口語體。或者,AI無法判斷代名詞(例如:它、他、她)所指為何,導致產生誤譯。
為了防止這種「拼接化」的情況,不僅需要提供要翻譯的差異資料,還必須將「周邊現有的翻譯內容」作為背景資訊(Context)一併提供給AI,這需要較為進階的實作方式。
解決問題的對策
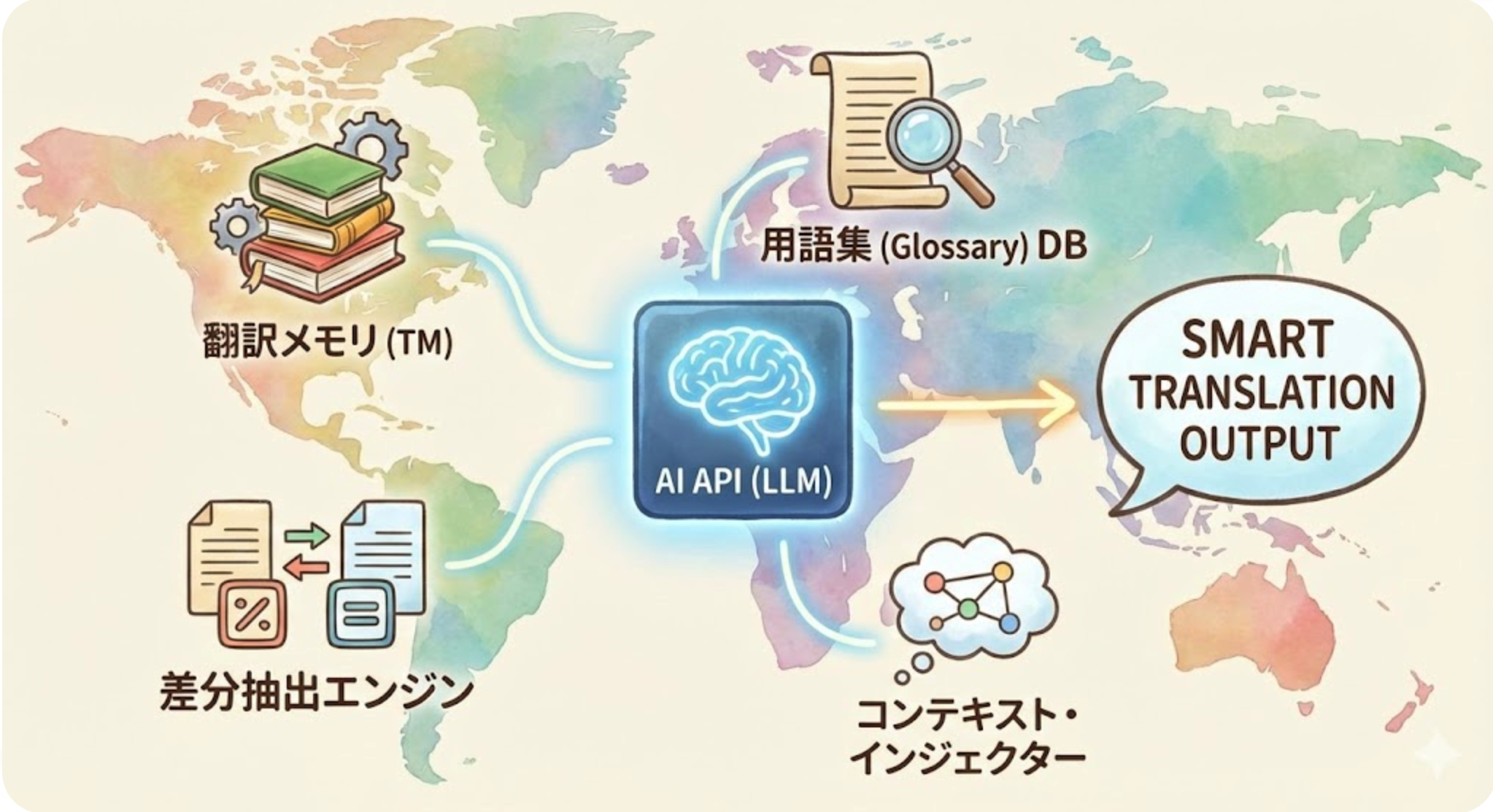
為了因應這些問題,不僅僅是單純呼叫 API,而是需要像以下這樣的 「翻譯協調(Orchestration)」 的觀點。
- 翻譯記憶體(TM)的運用:將過去的翻譯結果資料庫化,相同句子不重複翻譯,並參考類似句子。
- RAG(檢索增強生成)的方法:在翻譯時動態將術語表和過去的最佳實踐注入提示中。
- 情境注入:在進行差異翻譯時,將前後幾行作為「參考資訊」傳遞給API,以保持語氣一致。
總結
將AI翻譯整合進系統,不僅僅是語言轉換,更是一個「如何管理一致性」的工程挑戰。
不要因為「是AI就一定完美」而過度自信,應該在理解API特性的基礎上,思考如何維持上下文並建立用語控管的機制。這就是成功實現高品質多語言部署的關鍵。

