如果將 Google Translate(NMT)視為第三代,那麼以大型語言模型(LLM)為基礎的 AI 翻譯,可以說是第四代。
第四代的特點是,相較於第三代,可以更容易讓系統學習「術語」或「片語」翻譯方式的(某種)規則。
在這一點上,第4代與第1代(以規則為基礎)的機器翻譯非常相似。
第3代也有用語集的功能,像是 Google Translate 則有 AutoML 這類的遷移學習方法,可以依照自家需求進行調整,但副作用往往太強,經常導致翻譯品質下降。詞彙表的功能只能用於名詞,轉移學習(AutoML)的方法也過於繁瑣。而且,很難說這些方法真的有效。
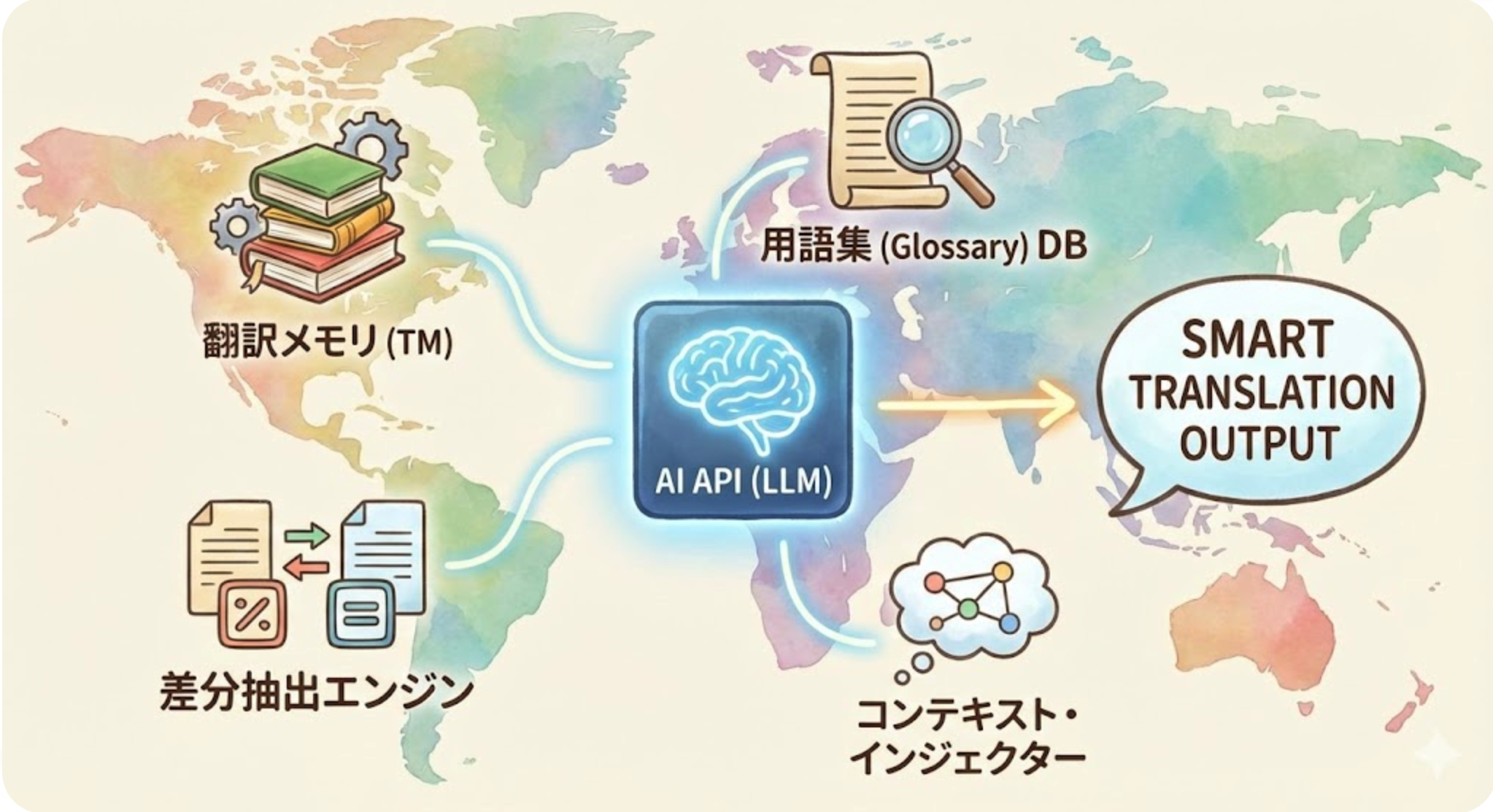
在第四代中,只要將用語或片語的翻譯規則登錄到系統即可,因為是以大型語言模型為基礎,所以可以像對人類下指令一樣來規定這些規則。
例如,想要將「製品」翻譯成「product」。雖然可以將這個詞登錄到字典中,但在第三代中,譯詞「product」會被固定為字串,無法自動變成複數形式,也不會在作為標題時自動轉為「Product」的大寫。在第 4 代中,系統會自動處理所需的詞形變化。
第 4 代已經讓翻譯者可以在個人層級上培養 AI 翻譯。在第 1 代以規則為基礎的機器翻譯時代,個別翻譯者需要購買機器翻譯軟體,並且一點一滴地登錄詞典,來培養機器翻譯的成果(雖然這是一種費力卻收穫甚少的徒勞努力)。在第 4 代也可以做到同樣的事情。
在第 4 代中,不僅可以登錄術語表,還可以登錄過去的翻譯資產——翻譯記憶體(TM)。也可以登錄片語層級的翻譯方式。而且,基礎的翻譯品質本身就相當不錯。可以在沒有副作用的情況下讓機器翻譯成長。
機器翻譯和AI翻譯的世代交替大約每10年發生一次。10年後應該會出現第5代,但完全無法想像會是什麼樣子。
然而,接下來的十年毫無疑問將會以第四代AI翻譯為主流。