近年来,随着Gemini和GPT-5等的出现,AI翻译的准确性得到了飞跃性的提升。然而,当尝试将这些技术集成到自有服务或业务系统中时,除了“翻译准确性好坏”之外,还会暴露出一系列严峻的运营问题。
1. “API集成”这一基本前提带来的限制
在实现翻译自动化和系统化时,不能手动复制粘贴到UI界面。基本上需要通过API(应用程序编程接口)来调用AI。
然而,API 是针对“每一次请求”返回“一个响应”的独立处理方式。它并不会像人类一样“记住上一次的翻译”。这种 无状态(不保存状态) 的特性,会引发接下来的“一致性”问题。
2. 每次调用API时变化的“风格”和“术语”
AI(尤其是大语言模型)即使输入相同的句子,也会因为当时的参数(如Temperature等)或对语境的理解不同,导致输出结果存在细微差异。
- 敬语风格与陈述风格混杂
- 特定专业术语有时被翻译为A,有时被翻译为B
为防止这种情况,必须在API调用时动态传入术语表(Glossary),或通过系统提示严格指定语气,构建控制层。
3. “成本”与“质量”的两难:差异更新的难题
在翻译网站或操作手册等更新频率较高的内容时,每次都进行“全文重新翻译”是非常低效的。
- 成本问题:即使只修改了几万字文档中的一行,如果重新翻译全文,API费用也会大幅增加。
- 质量问题:如果对全文重新翻译,未修改部分的表达方式也有可能发生变化,存在这样的风险。
因此,“仅识别并翻译已更新部分(差异翻译)” 的机制是必需的,但这也带来了下一个重大难题。
4. 上下文的断裂:拼接(拼布式)翻译的弊端
如果只将更新的部分交给AI,AI无法理解该部分的前后文。
例:前面的句子是用书面语写的,但新添加的那一句却被翻译成了口语体。或者,AI无法判断代词(它、他、她)指代的对象,从而导致翻译错误。
为了防止这种“拼接化”现象,不仅需要将待翻译的差异数据提供给AI,还需要将其周边已有的翻译文本作为上下文(背景信息)一并提供,这对实现方式提出了更高的要求。
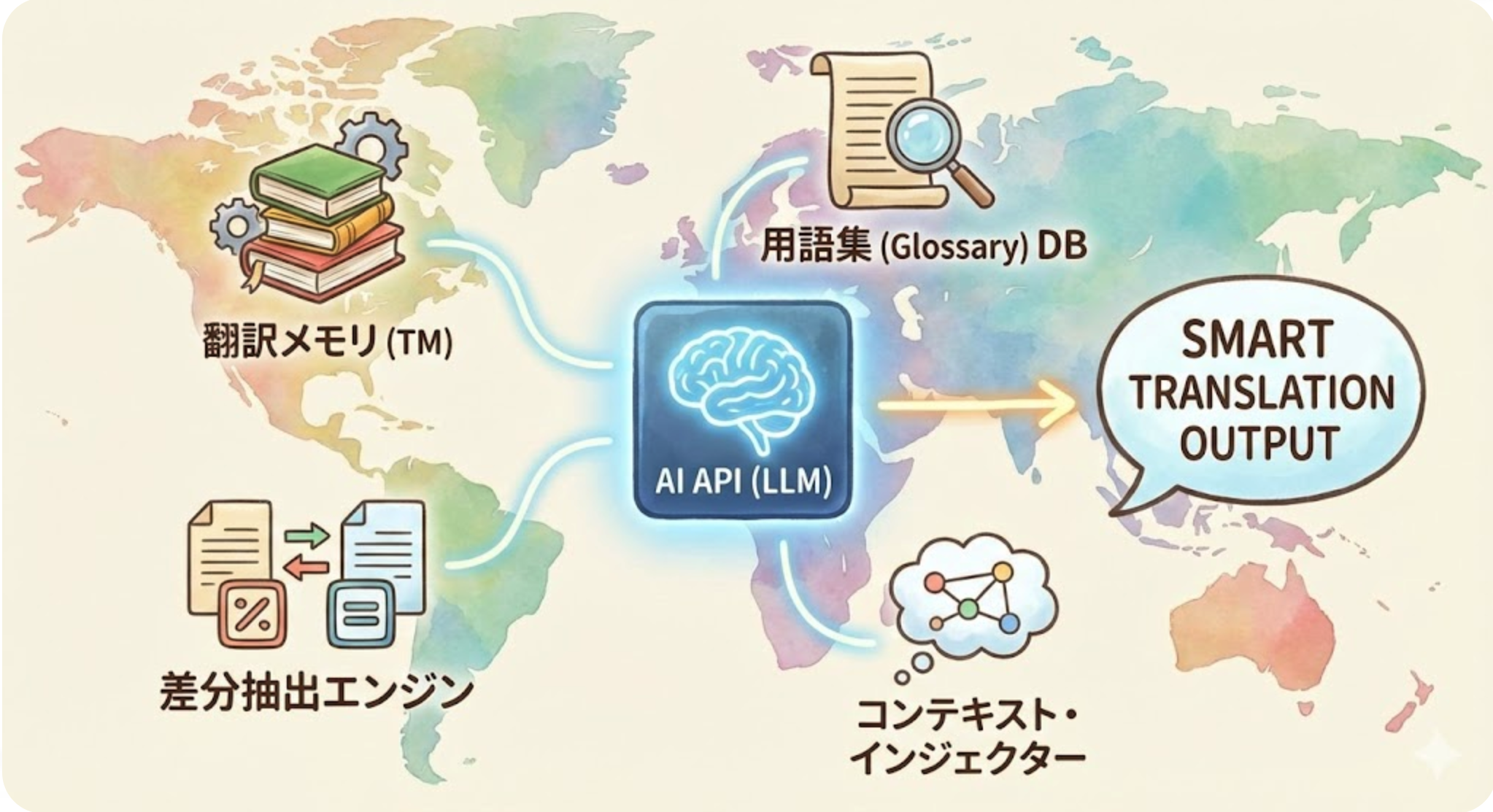
解决问题的方法
要应对这些问题,不仅仅是简单地调用API,还需要如下所述的“翻译编排”的视角。
- 翻译记忆(TM)的利用:将以往的翻译结果数据库化,对于相同的句子不再重新翻译,并参考相似的句子。
- RAG(检索增强生成)的方法:在翻译时动态地将术语表和以往的最佳实践注入到提示词中。
- 上下文注入:在进行差异翻译时,将前后几行作为“参考信息”传递给API,以保持语气一致。
总结
将AI翻译集成到系统中,不仅仅是语言转换,更是一个关于如何管理“一致性”的工程难题。
不要盲目信任“因为是AI就一定完美”,而是要在理解API特性的基础上,构建能够维持上下文和统一术语的机制。这正是实现高质量多语言部署的关键。

