近年、GeminiやGPT-5などの登場により、AI翻訳の精度は飛躍的に向上しました。しかし、これらを自社サービスや業務システムに統合しようとすると、単なる「翻訳精度の良し悪し」とは別の、運用上のシビアな問題が浮き彫りになってきます。
1. 「API連携」という大前提が生む制約
翻訳を自動化・システム化する場合、手動でUIにコピペするわけにはいきません。基本的にはAPI(Application Programming Interface)を介してAIを呼び出すことになります。
しかし、APIは「1回のリクエスト」に対して「1つのレスポンス」を返す独立した処理です。人間のように「前回の翻訳を覚えている」わけではありません。この ステートレス(状態を持たない) な性質が、次の「一貫性」の問題を引き起こします。
2. APIを叩くたびに変わる「テイスト」と「用語」
AI(特にLLM系)は、同じ文章を投げても、その時のパラメーター(Temperature等)や文脈の解釈によって、出力結果が微妙に異なる性質を持っています。
- です・ます調 vs である調が混在する
- 特定の専門用語が、ある時はA、ある時はBと訳される
これを防ぐには、API呼び出し時に「用語集(Glossary)」を動的に流し込んだり、システムプロンプトで厳格なトーン指定を行う「制御レイヤー」の構築が不可欠です。
3. 「コスト」と「品質」の板挟み:差分更新の難しさ
Webサイトやマニュアルなど、更新頻度が高いコンテンツを翻訳する場合、毎回「全文を再翻訳」するのは非効率です。
- コスト問題: 数万文字のドキュメントで1行だけ修正されたのに、全文を翻訳し直すとAPI費用が膨大になります。
- 品質問題: 全文を翻訳し直すと、修正していない箇所の言い回しまで変わってしまうリスクがあります。
そのため、 「更新された箇所だけを特定して翻訳する(差分翻訳)」 仕組みが必要になりますが、これが次の大きな課題を生みます。
4. コンテキストの断絶:継ぎ接ぎ(パッチワーク)翻訳の弊害
更新箇所だけをAIに投げると、AIはその部分の「前後の文脈」を把握できません。
例: 前の文章が「である調」で書かれているのに、新しく追加した1文だけが「です・ます調」で訳されてしまう。あるいは、代名詞(それ、彼、彼女)が何を指しているか分からず、誤訳が発生する。
この「パッチワーク化」を防ぐためには、翻訳対象の差分データだけでなく、「その周辺の既存の翻訳文」をコンテキスト(背景情報)としてAIに与えるという高度な実装が求められます。
課題を解決するためのアプローチ
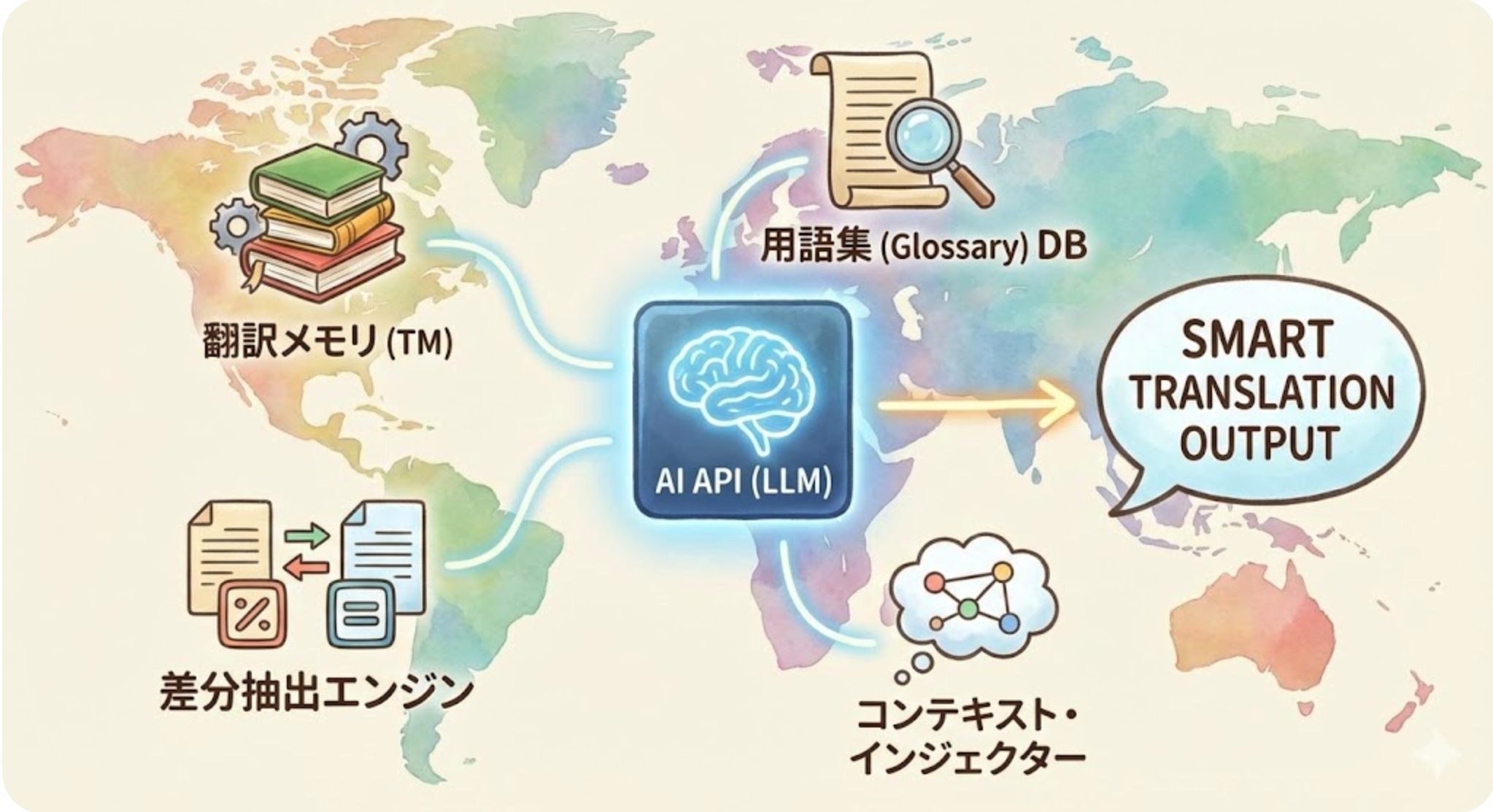
これらの問題に対処するためには、単なるAPI呼び出しではなく、以下のような 「翻訳オーケストレーション」 の視点が必要です。
- 翻訳メモリ(TM)の活用: 過去の翻訳結果をデータベース化し、同一文章は再翻訳せず、類似文章を参考にする。
- RAG(検索拡張生成)的アプローチ: 翻訳時に動的に用語集や過去のベストプラクティスをプロンプトに注入する。
- コンテキスト注入: 差分翻訳の際、前後の数行を「参考情報」としてAPIに渡し、トーンを合わせる。
まとめ
AI翻訳をシステムに組み込むことは、単なる言語変換ではなく、「一貫性をどう管理するか」というエンジニアリングの課題です。
「AIだから完璧」と過信せず、APIの特性を理解した上で、いかにコンテキストを維持し、用語を統制する仕組みを作るか。それが、高品質な多言語展開を成功させる鍵となります。

