최근 Gemini와 GPT-5 등의 등장으로 AI 번역의 정확도가 비약적으로 향상되었습니다. 하지만 이러한 기술을 자사 서비스나 업무 시스템에 통합하려고 하면, 단순한 '번역 정확도의 좋고 나쁨'과는 별개의, 운영상에서의 심각한 문제가 드러나기 시작합니다.
1. "API 연동"이라는 대전제가 만드는 제약
번역을 자동화하거나 시스템화할 때는, 수동으로 UI에 복사해서 붙여넣을 수는 없습니다. 기본적으로는 API(Application Programming Interface)를 통해 AI를 호출하게 됩니다.
하지만 API는 "한 번의 요청"에 대해 "하나의 응답"만을 반환하는 독립적인 처리입니다. 사람처럼 "이전 번역을 기억하고 있는" 것은 아닙니다. 이 스테이트리스(상태를 가지지 않는) 특성이 다음의 "일관성" 문제를 일으킵니다.
2. API를 호출할 때마다 달라지는 "톤"과 "용어"
AI(특히 LLM 계열)는 같은 문장을 입력해도, 그때의 파라미터(Temperature 등)나 문맥 해석에 따라 출력 결과가 미묘하게 달라지는 특성이 있습니다.
- 존댓말과 반말이 혼재되어 사용된다
- 특정 전문 용어가 어떤 때는 A로, 또 어떤 때는 B로 번역된다
이를 방지하려면 API 호출 시에 용어집(Glossary)을 동적으로 적용하거나, 시스템 프롬프트에서 엄격한 톤 지정을 수행하는 ‘제어 레이어’의 구축이 필수적입니다.
3. ‘비용’과 ‘품질’ 사이의 딜레마: 변경분 업데이트의 어려움
웹사이트나 매뉴얼 등 업데이트 빈도가 높은 콘텐츠를 번역할 때, 매번 ‘전체를 다시 번역’하는 것은 비효율적입니다.
- 비용 문제: 수만 자에 달하는 문서에서 한 줄만 수정되었더라도 전체를 다시 번역하면 API 비용이 크게 증가합니다.
- 품질 문제: 전체를 다시 번역하면 수정하지 않은 부분의 표현까지 바뀔 위험이 있습니다.
따라서 "업데이트된 부분만을 특정하여 번역하는(차등 번역)" 시스템이 필요하지만, 이것이 다음의 큰 과제를 낳습니다.
4. 컨텍스트의 단절: 패치워크(이어붙이기) 번역의 폐해
변경된 부분만 AI에 입력하면, AI는 해당 부분의 앞뒤 문맥을 파악할 수 없습니다.
예시: 이전 문장이 '이다체'로 작성되어 있는데, 새로 추가된 한 문장만 '입니다/습니다체'로 번역되는 경우가 있습니다. 또는, 대명사(그것, 그, 그녀)가 무엇을 가리키는지 알 수 없어 오역이 발생할 수 있습니다.
이러한 '패치워크화'를 방지하기 위해서는, 번역 대상의 차이 데이터뿐만 아니라, 그 주변의 기존 번역문을 컨텍스트(배경 정보)로 AI에 제공하는 고도화된 구현이 필요합니다.
문제를 해결하기 위한 접근법
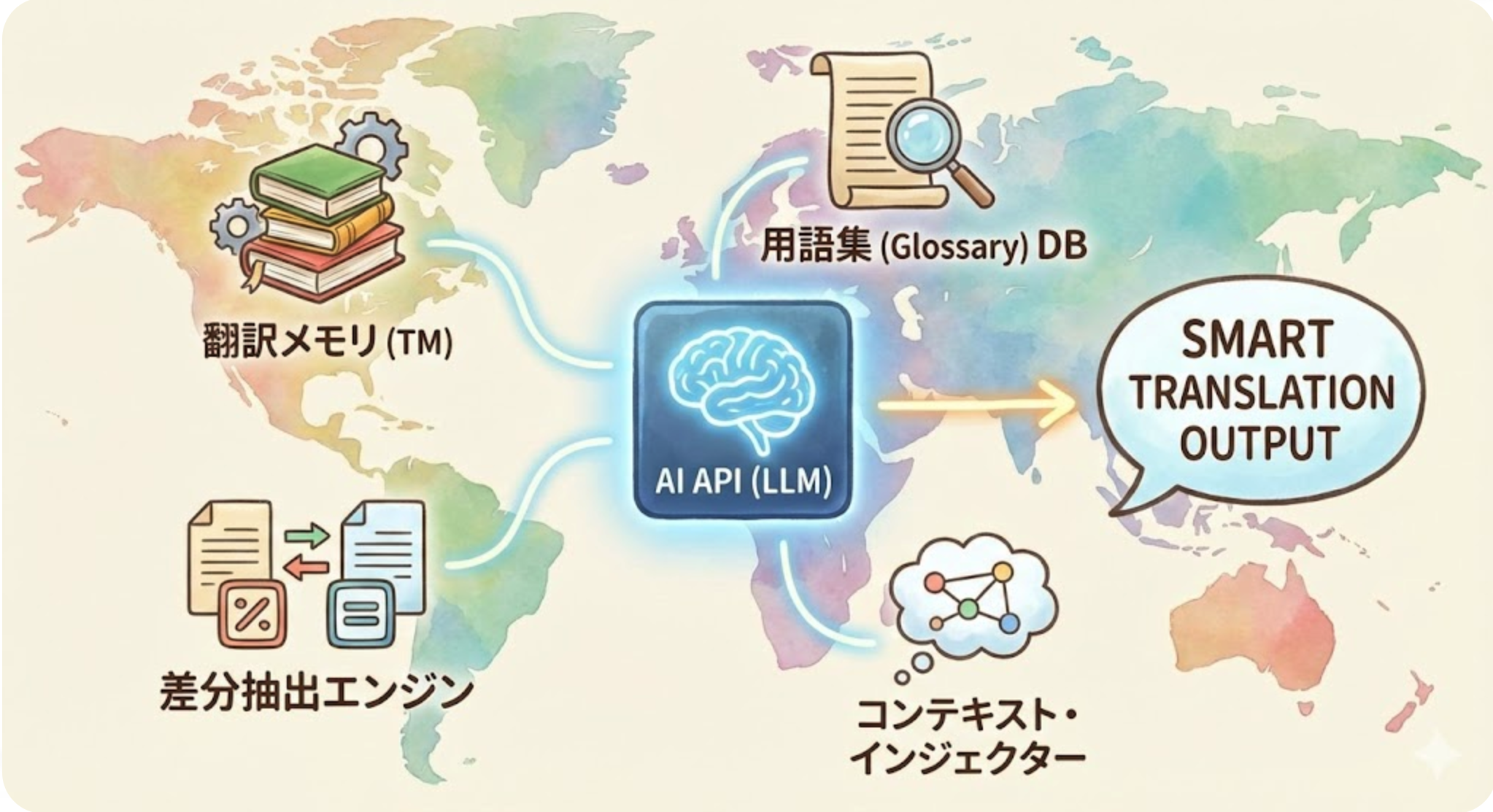
이러한 문제에 대응하기 위해서는 단순한 API 호출이 아니라, 아래와 같은 ‘번역 오케스트레이션’의 관점이 필요합니다.
- 번역 메모리(TM) 활용: 과거 번역 결과를 데이터베이스화하여 동일한 문장은 재번역하지 않고, 유사한 문장을 참고합니다.
- RAG(검색 확장 생성) 방식: 번역 시 동적으로 용어집이나 과거의 베스트 프랙티스를 프롬프트에 주입합니다.
- 컨텍스트 주입: 차이 번역 시 앞뒤 몇 줄을 '참고 정보'로 API에 전달하여 톤을 맞춘다.
정리
AI 번역을 시스템에 통합하는 것은 단순한 언어 변환이 아니라, '일관성을 어떻게 관리할 것인가'라는 엔지니어링 과제입니다.
"AI라서 완벽하다"고 과신하지 말고, API의 특성을 이해한 후 어떻게 컨텍스트를 유지하고 용어를 통제하는 시스템을 구축할 것인가가 중요합니다. 그것이 고품질 다국어 전개를 성공으로 이끄는 열쇠가 됩니다.

