ในช่วงไม่กี่ปีที่ผ่านมา ด้วยการมาของ Gemini และ GPT-5 ความแม่นยำของการแปลด้วย AI ได้พัฒนาขึ้นอย่างก้าวกระโดด อย่างไรก็ตาม เมื่อพยายามนำเทคโนโลยีเหล่านี้ไปผสานเข้ากับบริการหรือระบบงานขององค์กร จะพบปัญหาด้านการดำเนินงานที่ซับซ้อน ซึ่งแตกต่างจากแค่เรื่องความแม่นยำของการแปลเพียงอย่างเดียว
1. ข้อจำกัดที่เกิดจากข้อสมมติพื้นฐานเรื่อง "การเชื่อมต่อ API"
เมื่อจะทำให้การแปลเป็นอัตโนมัติหรือเป็นระบบ ไม่สามารถคัดลอกและวางใน UI ด้วยตนเองได้ โดยหลักแล้วจะต้องเรียกใช้งาน AI ผ่าน API (Application Programming Interface)
อย่างไรก็ตาม API เป็นกระบวนการที่ทำงานแยกกัน โดยจะส่งกลับ "ผลลัพธ์หนึ่งครั้ง" ต่อ "คำขอหนึ่งครั้ง" เท่านั้น API ไม่ได้ "จดจำการแปลครั้งก่อน" เหมือนกับมนุษย์ ลักษณะ สเตตเลส (ไม่มีสถานะ) นี้ก่อให้เกิดปัญหาเรื่อง "ความสม่ำเสมอ" ตามมา
2. "รสชาติ" และ "คำศัพท์" ที่เปลี่ยนไปทุกครั้งที่เรียกใช้ API
AI (โดยเฉพาะประเภท LLM) มีลักษณะที่ผลลัพธ์ที่ได้อาจแตกต่างกันเล็กน้อย แม้จะป้อนประโยคเดียวกันก็ตาม ขึ้นอยู่กับพารามิเตอร์ในขณะนั้น (เช่น Temperature) หรือการตีความบริบท
- รูปแบบประโยคสุภาพ vs รูปแบบประโยคบอกเล่า ปะปนกัน
- คำศัพท์เฉพาะบางคำ บางครั้งแปลเป็น A บางครั้งแปลเป็น B
เพื่อป้องกันปัญหานี้ จำเป็นต้องมีการสร้าง "เลเยอร์ควบคุม" เช่น การส่ง "ศัพท์เฉพาะ (Glossary)" แบบไดนามิกขณะเรียก API หรือการกำหนดโทนอย่างเข้มงวดใน system prompt
3. ความท้าทายระหว่าง "ต้นทุน" กับ "คุณภาพ": ความยากของการอัปเดตแบบเฉพาะจุด
เมื่อแปลเนื้อหาที่มีการอัปเดตบ่อย เช่น เว็บไซต์หรือคู่มือ การแปลใหม่ทั้งหมดทุกครั้งถือว่าไม่มีประสิทธิภาพ
- ปัญหาต้นทุน: แม้จะแก้ไขเพียง 1 บรรทัดในเอกสารที่มีหลายหมื่นตัวอักษร แต่หากต้องแปลใหม่ทั้งหมด ค่าบริการ API จะสูงมาก
- ปัญหาด้านคุณภาพ: หากแปลเนื้อหาทั้งหมดใหม่ มีความเสี่ยงที่สำนวนในส่วนที่ไม่ได้แก้ไขจะเปลี่ยนไปด้วย
ดังนั้นจึงจำเป็นต้องมีระบบที่สามารถระบุและแปลเฉพาะส่วนที่มีการอัปเดต (การแปลเฉพาะส่วนที่เปลี่ยนแปลง) แต่สิ่งนี้ก็ทำให้เกิดปัญหาใหญ่ถัดไป
4. การขาดบริบท: ผลกระทบของการแปลแบบปะติดปะต่อ (Patchwork)
หากส่งเฉพาะส่วนที่มีการอัปเดตให้ AI แปล AI จะไม่สามารถเข้าใจ "บริบทก่อนและหลัง" ของส่วนนั้นได้
ตัวอย่าง: แม้ว่าประโยคก่อนหน้าจะเขียนด้วยรูปแบบทางการ แต่ประโยคใหม่ที่เพิ่มเข้ามากลับถูกแปลด้วยรูปแบบสุภาพ หรือบางครั้ง AI ไม่สามารถเข้าใจได้ว่าคำสรรพนาม (เช่น นั้น, เขา, เธอ) หมายถึงอะไร ส่งผลให้เกิดการแปลผิดพลาด
เพื่อป้องกันปัญหา "การแปลแบบปะติดปะต่อ" นี้ จำเป็นต้องมีการพัฒนาอย่างล้ำลึกที่ไม่เพียงแค่ให้ข้อมูลส่วนที่เปลี่ยนแปลงสำหรับการแปลเท่านั้น แต่ยังต้องให้ "ข้อความแปลที่มีอยู่รอบข้าง" เป็นบริบท (ข้อมูลพื้นหลัง) แก่ AI ด้วย
แนวทางในการแก้ไขปัญหา
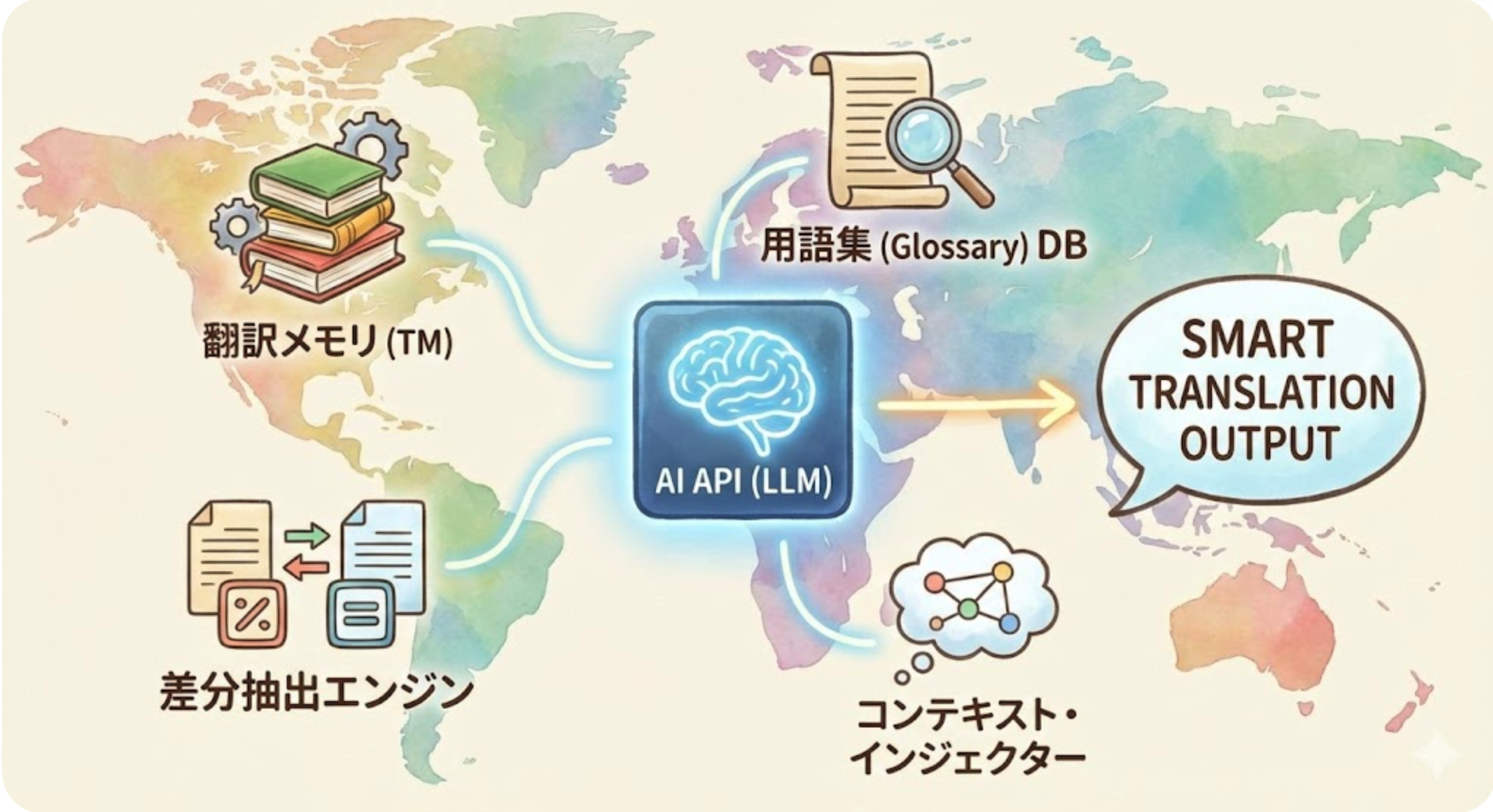
ในการรับมือกับปัญหาเหล่านี้ ไม่ใช่แค่การเรียกใช้งาน API ธรรมดา แต่จำเป็นต้องมีมุมมองแบบ “การจัดการกระบวนการแปล (Translation Orchestration)” ดังต่อไปนี้
- การใช้หน่วยความจำการแปล (TM): จัดเก็บผลลัพธ์การแปลที่ผ่านมาไว้ในฐานข้อมูล โดยไม่แปลประโยคเดียวกันซ้ำ และใช้ประโยคที่คล้ายกันเป็นข้อมูลอ้างอิง
- แนวทางแบบ RAG (การสร้างผลลัพธ์ด้วยการค้นหาเพิ่มเติม): ขณะทำการแปล จะใส่คำศัพท์หรือแนวปฏิบัติที่ดีที่สุดในอดีตลงในพรอมต์แบบไดนามิก
- การใส่คอนเท็กซ์: ในการแปลเฉพาะส่วน ให้ส่งประโยคก่อนหน้าและหลังจากนั้นสองสามบรรทัดเป็น "ข้อมูลอ้างอิง" ไปยัง API เพื่อให้โทนสอดคล้องกัน
สรุป
การนำ AI แปลภาษาเข้ามาในระบบ ไม่ใช่แค่การแปลงภาษาเท่านั้น แต่เป็นโจทย์ทางวิศวกรรมเกี่ยวกับ "การจัดการความสอดคล้องของเนื้อหา"
อย่าเชื่อมั่นว่า "เพราะเป็น AI แล้วจะสมบูรณ์แบบ" แต่ควรเข้าใจลักษณะเฉพาะของ API และสร้างระบบที่สามารถรักษาคอนเท็กซ์และควบคุมคำศัพท์ได้อย่างเหมาะสม นั่นคือกุญแจสำคัญในการขยายบริการหลายภาษาให้มีคุณภาพสูงและประสบความสำเร็จ

