第 4 世代の AI 翻訳は先祖返りなのか?

Google Translate (NMT) を第 3 世代とするなら、大規模言語モデル (LLM) を土台とする AI 翻訳は、第 4 世代と言えるだろう。
第 4 世代の特徴は、第 3 世代と比べて、「用語」や「フレーズ」の翻訳の仕方の(ある種の)ルールを簡単に学習させることができることと言える。
その点で第 4 世代は、第 1 世代(ルールベース)の機械翻訳ととても似ている。
第 3 世代も、用語集の機能があったり、Google Translate であれば AutoML といった転移学習の手法はあって、自社好みにチューニングすることができたが、あまりに副作用が強すぎて、訳出品質の劣化につながることもしばしばあった。用語集の機能は名詞にしか使えず、転移学習 (AutoML) の手法も煩雑にすぎた。そして、効果があるとは言いづらかった。
第 4 世代では、用語やフレーズの翻訳の仕方のルールをシステムに登録すればよいのだが、大規模言語モデルを土台にしているから、人間に対して指示を出すときと同じ形でルールを規定できる。
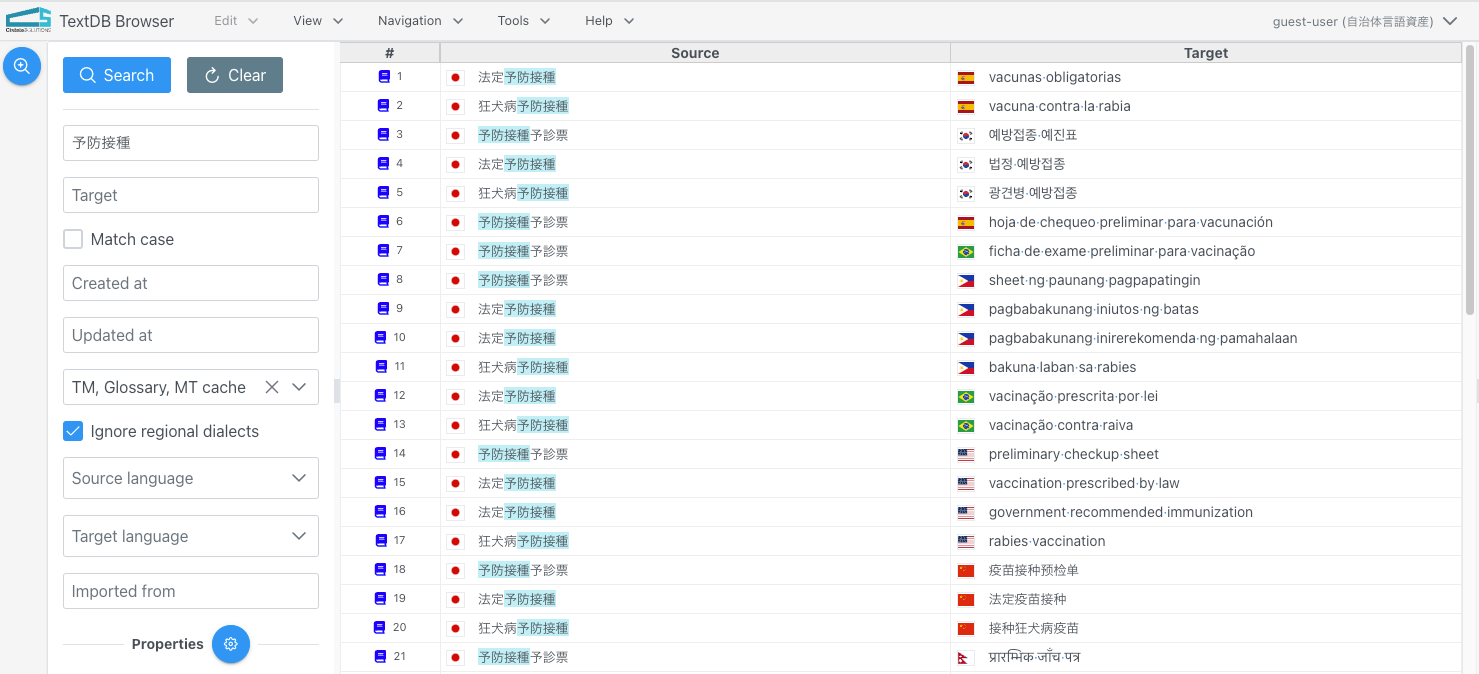
たとえば、「製品」を「product」と翻訳したいとする。これを辞書に登録するわけだが、第 3 世代では、訳語の「product」は文字列として固定されてしまって、複数形の活用もされないし、見出しのときに「Product」とキャピタライズされることもない。第 4 世代では、必要な活用形の処理を行ってくれる。
第 4 世代は、翻訳者個人のレベルで AI 翻訳を育てていくことができるようになった。第 1 世代のルールベースの機械翻訳では、個人の翻訳者が機械翻訳ソフトウェアを購入して、個人がコツコツ辞書登録をして、機械翻訳の結果を育てていた(それは労多くして実り少ない不毛な努力であったが)。第 4 世代でも同じことができる。
第 4 世代では、用語集も登録できるし、過去の翻訳資産である翻訳メモリー (TM) を登録することもできる。フレーズレベルの訳し方を登録することもできる。そして、ベースの翻訳品質自体がかなり良い。副作用もなく機械翻訳を成長させることができる。
機械翻訳・AI 翻訳の世代交代はだいたい 10 年ごとに起きる。10 年後には第 5 世代が登場するのだろうし、それがどんな姿なのかまったく想像がつかない。
しかし、これからの 10 年は間違いなく第 4 世代の AI 翻訳が中心になる。